Jonathan Dowland: cherished



 It's been quiet here (I hope to change that), but I want to share some good
news: I've been promoted to Principal Software Engineer! Next February will
start my 9th year with Red Hat. Time flies when you're
having fun!
It's been quiet here (I hope to change that), but I want to share some good
news: I've been promoted to Principal Software Engineer! Next February will
start my 9th year with Red Hat. Time flies when you're
having fun!

 A couple of releases
Now that it's more convenient for me to run containers at
home, I thought I'd write a bit about web apps I am enjoying.
First up, FreshRSS, a web feed aggregator. I used to
make heavy use of Google Reader until Google killed
it, and although a bunch of self-hosted cloned sprung up very quickly
afterwards, I didn't transition to any of them.
Then followed a number of years within which, in retrospect, I basically didn't
do a great job of organising reading the web. This lasted until a couple of
years ago when, on a whim, I tried out NetNewsWire
for iOS. NetNewsWire is a well-established and much-loved feed reader for Mac
which I've never used. I used the iOS version in isolation for a long time:
only dipping into web feeds on my phone and never on another device.
I'd like to see the old web
back, and do my part to
make that happen. I've continually published
rss and atom
feeds for my own blog. I'm also trying to
blog more: this might be easier now that Twitter (which, IMHO, took a lot of
the energy for quick writing out of blogging) is mortally wounded.
So, I'm giving FreshRSS a go. Early signs are good: it's fast, lightweight,
easy to use, vaguely resembles how I remember Google Reader, and has a native
dark-mode. It's still early days building up a new list of feeds to follow.
I'll be sure to share interesting ones as I discover them!
A couple of releases
Now that it's more convenient for me to run containers at
home, I thought I'd write a bit about web apps I am enjoying.
First up, FreshRSS, a web feed aggregator. I used to
make heavy use of Google Reader until Google killed
it, and although a bunch of self-hosted cloned sprung up very quickly
afterwards, I didn't transition to any of them.
Then followed a number of years within which, in retrospect, I basically didn't
do a great job of organising reading the web. This lasted until a couple of
years ago when, on a whim, I tried out NetNewsWire
for iOS. NetNewsWire is a well-established and much-loved feed reader for Mac
which I've never used. I used the iOS version in isolation for a long time:
only dipping into web feeds on my phone and never on another device.
I'd like to see the old web
back, and do my part to
make that happen. I've continually published
rss and atom
feeds for my own blog. I'm also trying to
blog more: this might be easier now that Twitter (which, IMHO, took a lot of
the energy for quick writing out of blogging) is mortally wounded.
So, I'm giving FreshRSS a go. Early signs are good: it's fast, lightweight,
easy to use, vaguely resembles how I remember Google Reader, and has a native
dark-mode. It's still early days building up a new list of feeds to follow.
I'll be sure to share interesting ones as I discover them!

 Lots of mid-90s games had very boxy floors
Lots of mid-90s games had very boxy floors
](https://jmtd.net/log/zarchscape/carpet_90s.jpg) Terrain generation, 90s-style. From this article
Terrain generation, 90s-style. From this article

 IZ #294, the latest issue
IZ #294, the latest issue
 IZ #194: The first by TTA press
My daughter Beatrice asked for me to print her a 3D printer.
IZ #194: The first by TTA press
My daughter Beatrice asked for me to print her a 3D printer.
 Bea's 3D printer
I've moved to having containers be first-class citizens on my home network, so
any local machine (laptop, phone,tablet) can communicate directly with them all,
but they're not (by default) exposed to the wider Internet. Here's why, and how.
After I moved containers from docker to Podman and
systemd, it became much more convenient to run web apps on
my home server, but the default approach to networking
(each container gets an address on a private network between the host server
and containers) meant tedious work (maintaining and reconfiguring a HTTP
reverse proxy) to make them reachable by other devices. A more attractive
arrangement would be if each container received an IP from the range used by
my home LAN, and were automatically addressable from any device on it.
To make the containers first-class citizens on my home LAN, first I needed to
configure a Linux network bridge and attach the host machine's interface to it
(I've done that many times before);
then define a new Podman network, of type "bridge". podman-network-create
(1)
serves as reference, but the blog post Exposing Podman containers fully on the
network
is an easier read (skip past the
Bea's 3D printer
I've moved to having containers be first-class citizens on my home network, so
any local machine (laptop, phone,tablet) can communicate directly with them all,
but they're not (by default) exposed to the wider Internet. Here's why, and how.
After I moved containers from docker to Podman and
systemd, it became much more convenient to run web apps on
my home server, but the default approach to networking
(each container gets an address on a private network between the host server
and containers) meant tedious work (maintaining and reconfiguring a HTTP
reverse proxy) to make them reachable by other devices. A more attractive
arrangement would be if each container received an IP from the range used by
my home LAN, and were automatically addressable from any device on it.
To make the containers first-class citizens on my home LAN, first I needed to
configure a Linux network bridge and attach the host machine's interface to it
(I've done that many times before);
then define a new Podman network, of type "bridge". podman-network-create
(1)
serves as reference, but the blog post Exposing Podman containers fully on the
network
is an easier read (skip past the macvlan bit).
I've opted to choose IP addresses for each container by hand. The Podman
network is narrowly defined to a range of IPs that are within the subnet that
my ISP-provided router uses, but outside the range of IPs that it allocates.
When I start up a container by hand for the first time, I choose a free IP from
the sub-range by hand and add a line to /etc/avahi/hosts on the parent
machine, e.g.
192.168.1.33 octoprint.local
podman run --rm -d --name octoprint \
...
--network bridge_local --ip 192.168.1.33 \
octoprint/octoprint
octoprint.local.
What's next
Although it's not a huge burden, it would be nice to not need to statically
define the addresses in /etc/avahi/hosts (perhaps via "IPAM"). I've also been
looking at
WireGuard
(which should be the subject of a future blog post) and combining this with
that would be worthwhile.
I've been watching the neovim community for a while and what seems like a
cambrian explosion of plugins emerging. A few weeks back I decided to spend
most of a "day of learning" on investigating some of the plugins and
technologies that I'd read about: Language Server
Protocol,
TreeSitter,
neorg (a grandiose organiser plugin),
etc.
It didn't go so well. I spent most of my time fighting version
incompatibilities or tracing through scant documentation or code to figure out
what plugin was incompatible with which other.
There's definitely a line where crossing it is spending too much time playing
with your tools instead of creating. On the other hand, there's definitely
value in honing your tools and learning about new technologies. Everyone's line
is probably in a different place. I've come to the conclusion that I don't have
the time or inclination (or both) to approach exploring the neovim universe in
this way. There exist a number of plugin "distributions" (such as LunarVim): collections of pre-
configured and integrated plugins that you can try to use out-of-the-box. Next
time I think I'll pick one up and give that a try &emdash independently
from my existing configuration &emdash and see which ideas from it I might like to
adopt.
shared vimrcs
Some folks upload their vim or neovim configurations in their entirety for
others to see. I noticed Jess Frazelle had published
hers so I took a look. I suppose one could
evaluate a bunch of plugins and configuration in isolation using a shared vimrc
like this, in the same was as a distribution.
bufferline
Amongst the plugins she uses was bufferline, a plugin to re-work neovim's
tab bar to behave like tab bars from more conventional editors1. I don't make
use of neovim's tabs at all2, so I would lose nothing having the (presently hidden)
tab bar reworked, so I thought I'd give it a go.
I had to disable an existing plugin lightline, which I've had enabled for years
but I wasn't sure I was getting much value from. Apparently it also messes with the
tab bar! Disabling it, at least for now, at least means I'll find out if I miss it.
I am already using
vim-buffergator as a means
of seeing and managing open buffers: a hotkey opens a sidebar with a list of
open buffers, to switch between or close. Bufferline gives me a more immediate,
always-present view of open buffers, which is faintly useful: but not much.
Perhaps I'd like it more if I was coming from an editor that had made it more
of an expected feature. The two things I noticed about it that aren't
especially useful for me: when browsing around vimwiki pages, I quickly
open a lot of buffers. The horizontal line fills up very quickly. Even when I
don't, I habitually have quite a lot of buffers open, and the horizontal line
is quickly overwhelmed.
I have found myself closing open buffers with the mouse, which I didn't do
before.
vert
Since I have brought up a neovim UI feature (tabs) I thought I'd briefly mention
my new favourite neovim built-in command: vert.
Quite a few plugins and commands open up a new window (e.g. git-fugitive,
Man, etc.) and they typically do so in a horizontal split. I'm increasingly
preferring vertical splits. Prefixing any3 such command with vert forces
the split to be vertical instead.
I wanted to start using (neo)mutt's sidebar and I wanted a way
of separating groups of mail folders in the list. To achieve
that I interleaved a couple of fake "divider" folder names.
It looks like this:
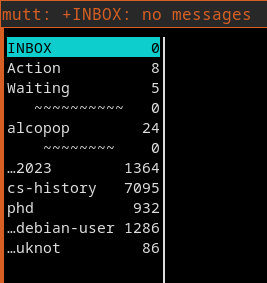 Screenshot of neomutt with sidebar
Screenshot of neomutt with sidebar
set sidebar_sort_method = 'unsorted'
mailboxes =INBOX =Action =Waiting
mailboxes '= ~~~~~~~~' # divider
...
family:liabilities:jon means "family owes jon". A
coffee bought by mistake on the family credit card will have a negative
posting on the credit card, and thus a positive one on the liabilities
account. ("jon owes family"). That's fine.
But what about when I buy family stuff on a personal card? The other side of
of the transaction is also going to have a positive sign, so it can't be
posted to family:liabilities:jon: it would have to go to somewhere else,
like jon:liabilities:family. Now I have two accounts which track versions
of the same thing, and they cannot be combined with a simple transaction
since they're looking at the same value from opposite directions (and signs).
Back when I first described the problem I was using
a single journal file for all my transactions. After moving to lots of separate
journal files (in hledger 1yr), it's become clearer to me that I don't
need to maintain the Family and Personal data together, at all: they can be
entirely separate journals.
getting data between journals
When I moved to a new set of ledger files for 2023, I needed to carry forward
the balances from 2022 in the form of "opening balance" transactions. This was
achieved by a report on the 2022 data, exported as CSV, and imported into the
2023 data (all following the scheme outlined by fully-fledged hledger.))
Separate Personal and Family journals need some information from each other, and I
can achieve that in the same way as for opening balances: with an export of
the relevant transactions as CSV, then imported on the other side. HLedger's
CSV import system is flexible enough that we can effectively invert the sign
of liabilities, addressing the problem above.
Worked example
We start with an accidental coffee purchased on the family card (and so this
belongs to the Family ledger)
2022-08-20 coffee
liabilities:creditcard -3
liabilities:jon:expenses:coffee 3
expenses:coffee) as a sub-account of the liabilities
category that the Family ledger is interested in1 (the first bit,
liabilities:jon). When viewed on the Family side, the expense category is not
interesting, and we can hide it with HLedger's alias feature2:
alias /^liabilities:jon(.*)$/ = liabilities:jon
2022-08-20 coffee
liabilities:creditcard -3
liabilities:jon 3
hledger reg -f family/2023-back.journal liabilities:jon: -O csv \
jon/import/family/liabilities.csv
liabilities:jon: is important here!)
In the resulting CSV file, the running example transaction looks like
"55","2022-08-20","","coffee","liabilities:jon:expenses:coffee"," 3.00"," 3.00"
hledger import. The rules file
for the import is very simple: the fields date, description, account1
and amount are taken as-is; account2 is hard-coded to liabilities:family.
The resulting transaction looks like
2022-08-20 coffee
liabilities:jon:expenses:coffee 3
liabilities:family -3
liabilities:jon: prefix. The import rules can't do
this3 , so we use another journal file as a go-between with another alias
rule:
alias /^liabilities.jon:/ =
2022-08-20 coffee
expenses:coffee 3
liabilities:family -3
hledger reg report. That's what the trailing
colon is for: It ensures I only export transactions which are to a sub-account
of liabilities:jon, and not to the root account liabilities:jon itself:
which is where I put the repayment transactions. I could instead use a more
explicit sub-account like liabilities:jon:repayments or similar, since the
trailing colon is quite subtle, but this works for me.
Wrap up
I've been really on the fence as to whether the complexity of this scheme is
worth it to avoid the virtual postings. The previous scheme was much simpler.
I have definitely made some mistakes with it, which didn't get caught by the
double-entry rules that virtual postings ignore, but they're for small sums
of money anyway.
On the other hand, a lot of the "machinery" of this already existed for getting
opening balances between calendar years, and the gory details are written down
and hidden inside the Makefile. I also expect that I will continue to see
advantages in having Family and Personal entirely separate, as they can each
develop and adapt to their own needs without having to consider the other side
of things every time.
It's a running experiment, and time will tell if it's a good idea.
family/2023.journal
file, which imports the data from another family/2023-back.journal,
and the CSV export is performed on the backing journal with the data
and not the alias. I've been pondering what should happen to personal websites once the owner has
passed, or otherwise "moved on". Some time ago I stumbled across a blog by Kev
Quirk, who wrote
I d need to come up with contingency plans for...This website, and any other websites and own/manageI thought it was a strange idea, to have a contingency plan for a personal site to survive its writer. Even a site such as my own, which (as sites go) would be trivial to host/mirror (since it's static), who would want to do that? Why would they do that? On the other hand, whether something I've written is useful or not is largely independent of whether I'm alive and well. And if anything I've written is useful independently from me (to pick a recent example, my notes on imaging optical media), should it persist somewhere? I've long thought of personal sites much like any website, which is to say, implicitly eternal, despite mountains of evidence that practically the reverse is true. I was influenced a long time ago by the article Cool URIs don't change. Thinking more about "digital legacy" led me to start believing that personal sites are ultimately not the right place for any kind of content that should have some persistence. (You might well have started with that assumption!) Yesterday via Planet Debian I read Aur lien Jarno's recent blog post where they have deprecated all of their personal site bar their blog. Quoting Aur lien:
Wikipedia is a much better platform for sharing knowledge than random websites.This struck me as an interesting idea. Wikipedia is a reasonable place for a lot of material that might otherwise be hosted on personal sites, and as a "living website", content can be adapted, corrected, etc. over time. Wikipedia is clearly not the right place for much other material that might exist on personal sites (it's not the right place for my aforementioned article). I'm not sure where might be. Perhaps we, as a culture, need to move away from the notion of personal sites, and devise a more collective concept. Or perhaps it's no bad thing that, without intervention, this stuff disappears.
I was asked on the Fediverse1 to describe my $dayjob daily
workflow. Blogging about it seemed like a good opportunity to take stock of my
current setup.
The core of my approach is to maintain a daily log, rather like an engineering
Lab Book2. My number one tip for anyone starting a career in Software
Engineering (or for that matter systems administration) is to keep a daily log
of what you intended to do, what you actually did, what you changed, what
changed as a consequence, etcetera. I've already written about the tools I use
for that: vimwiki.
They key drawback of that system is managing TODO lists. In Vimwiki, tasks look
like this:
* [ ] buy milk (still todo)
* [X] clean the car (done)
= Backlog +redhat status:pending =
* [ ] buy milk (still todo)
...

 I haven t done one of these for a while, and they ll be less frequent than I
once planned as I m working from home less and less. I'm also trying to get
back into exploring my digital music collection, and more generally engaging
with digital music again.
I haven t done one of these for a while, and they ll be less frequent than I
once planned as I m working from home less and less. I'm also trying to get
back into exploring my digital music collection, and more generally engaging
with digital music again.
 My credit card and bank account rarely agree on the date for when I pay it off1.
Since I added balance assertions for bank account transactions,
I need the transaction in my ledger to match what the bank thinks, otherwise
the balance assertions would start to fail.
The skew is not normally more than a couple of days, and could be corrected by
changing the date for just one of the two
postings. But the skew is
not very important, and altering the posting date could be used for something
more useful.
date warping credit card repayments
My credit card bills land halfway through the month, so February's bill covers
transactions between January 15th and February 14th. I pay off the bill in full
each month using Direct Debit. The credit card company consider the bill paid
immediately, but they don't actually draw it until the end of the month (Jan 31
in the running example). This means the payment transaction for a given month
lands halfway through the period covered by the next month's bill.
The credit card bill itself shows the payment date at the end of the month but
presents the transaction "warped" right to the start. This is actually useful,
because it means the balance is zero for the first purchase on the bill.
The credit card data in CSV form has the repayment transaction at the date it
occurred, not warped to the start of the period. When I import this into
HLedger, the credit card account balance for each new transaction does not match
the statement right up to the point of the repayment, half way through. This
makes spot-checking that the imported data matches the statement a bit more
awkward.
So, I have started "warping" the payment transaction to the start of the
billing period, just like the credit card statement does:
My credit card and bank account rarely agree on the date for when I pay it off1.
Since I added balance assertions for bank account transactions,
I need the transaction in my ledger to match what the bank thinks, otherwise
the balance assertions would start to fail.
The skew is not normally more than a couple of days, and could be corrected by
changing the date for just one of the two
postings. But the skew is
not very important, and altering the posting date could be used for something
more useful.
date warping credit card repayments
My credit card bills land halfway through the month, so February's bill covers
transactions between January 15th and February 14th. I pay off the bill in full
each month using Direct Debit. The credit card company consider the bill paid
immediately, but they don't actually draw it until the end of the month (Jan 31
in the running example). This means the payment transaction for a given month
lands halfway through the period covered by the next month's bill.
The credit card bill itself shows the payment date at the end of the month but
presents the transaction "warped" right to the start. This is actually useful,
because it means the balance is zero for the first purchase on the bill.
The credit card data in CSV form has the repayment transaction at the date it
occurred, not warped to the start of the period. When I import this into
HLedger, the credit card account balance for each new transaction does not match
the statement right up to the point of the repayment, half way through. This
makes spot-checking that the imported data matches the statement a bit more
awkward.
So, I have started "warping" the payment transaction to the start of the
billing period, just like the credit card statement does:
2022-12-31 pay credit card
asset:bank -500
liabilities:credit card ; date:2022-12-15
2023-01-25 buy some shoes. hedging on the size
liabilities:credit card -200
expenses:shoes
2023-02-05 return the ones that don't fit
liabilities:credit card 150
expenses:shoes
Balance changes in 2023-01-01..2023-02-28:
$ hledger bal -Mt expenses:shoes
Jan Feb
================++===============
expenses:shoes 200 -150
----------------++---------------
200 -150
2023-02-05 return the ones that don't fit
liabilities:credit card 150
expenses:shoes ; date:2023-01-25
$ hledger bal -Mt expenses:shoes
Balance changes in 2023-01-01..2023-02-28:
Jan Feb
================++===========
expenses:shoes 50 0
----------------++-----------
50 0


 The Reception
The Reception
 SLS Farm in the former Hack lab
SLS Farm in the former Hack lab
 History of the MK3S+
History of the MK3S+
 A Historic display
A Historic display
 Bespoke QE equipment
Bespoke QE equipment
 The MK3S+ Farm
The MK3S+ Farm
 Moi in the Farm
Moi in the Farm
 2KG orange PLA spools for the Farm
It's been a year since I started exploring HLedger, and I'm still
going. The rollover to 2023 was an opportunity to revisit my approach.
Some time ago I stumbled across Dmitry Astapov's HLedger notes (fully-fledged
hledger, which I briefly
mentioned in eventual consistency) and decided to adopt some of its ideas.
new year, new journal
First up, Astapov encourages starting a new journal file for a new calendar
year. I do this for other, accounting-adjacent files as a matter of course,
and I did it for my GNUCash files prior to adopting HLedger. But the reason
for those is a general suspicion that a simple mistake with those softwares
could irrevocably corrupt my data. I'm much more confident with HLedger, so
rolling over at years end isn't necessary for that. But there are other
advantages. A quick obvious one is you can get rid of old accounts (such as
expense accounts tied to a particular project, now completed).
one journal per import
In the first year, I periodically imported account data via CSV exports
of transactions and HLedger's (excellent) CSV import system. I imported
all the transactions, once each, into a single, large journal file.
Astapov instead advocates for creating a separate journal
for each CSV that you wish to import, and keep around the CSV, leaving you
with a 1:1 mapping of CSV:journal. Then use HLedger's "include" mechanism to
pull them all into the main journal.
With the former approach, where the CSV data was imported precisely, once, it
was only exposed to your import rules once. The workflow ended up being:
import transactions; notice some that you could have matched with import rules
and auto-coded; write the rule for the next time. With Astapov's approach, you
can re-generate the journal from the CSV at any point in the future with an
updated set of import rules.
tracking dependencies
Now we get onto the job of driving the generation of all these derivative
journal files. Astapov has built a sophisticated system using Haskell's "Shake",
which I'm not yet familiar, but for my sins I'm quite adept at (GNU-flavoured)
UNIX Make, so I started building with that. An example rule
2KG orange PLA spools for the Farm
It's been a year since I started exploring HLedger, and I'm still
going. The rollover to 2023 was an opportunity to revisit my approach.
Some time ago I stumbled across Dmitry Astapov's HLedger notes (fully-fledged
hledger, which I briefly
mentioned in eventual consistency) and decided to adopt some of its ideas.
new year, new journal
First up, Astapov encourages starting a new journal file for a new calendar
year. I do this for other, accounting-adjacent files as a matter of course,
and I did it for my GNUCash files prior to adopting HLedger. But the reason
for those is a general suspicion that a simple mistake with those softwares
could irrevocably corrupt my data. I'm much more confident with HLedger, so
rolling over at years end isn't necessary for that. But there are other
advantages. A quick obvious one is you can get rid of old accounts (such as
expense accounts tied to a particular project, now completed).
one journal per import
In the first year, I periodically imported account data via CSV exports
of transactions and HLedger's (excellent) CSV import system. I imported
all the transactions, once each, into a single, large journal file.
Astapov instead advocates for creating a separate journal
for each CSV that you wish to import, and keep around the CSV, leaving you
with a 1:1 mapping of CSV:journal. Then use HLedger's "include" mechanism to
pull them all into the main journal.
With the former approach, where the CSV data was imported precisely, once, it
was only exposed to your import rules once. The workflow ended up being:
import transactions; notice some that you could have matched with import rules
and auto-coded; write the rule for the next time. With Astapov's approach, you
can re-generate the journal from the CSV at any point in the future with an
updated set of import rules.
tracking dependencies
Now we get onto the job of driving the generation of all these derivative
journal files. Astapov has built a sophisticated system using Haskell's "Shake",
which I'm not yet familiar, but for my sins I'm quite adept at (GNU-flavoured)
UNIX Make, so I started building with that. An example rule
import/jon/amex/%.journal: import/jon/amex/%.csv rules/amex.csv.rules
rm -f $(@D)/.latest.$*.csv $@
hledger import --rules-file rules/amex.csv.rules -f $@ $<
import/opening/2023.csv: 2022.journal
mkdir -p import/opening
hledger bal -f $< \
$(list_of_accounts_I_want_to_carry_over) \
-O csv -N > $@
import/opening/2023.journal: import/opening/2023.csv rules/opening.rules
rm -f $(@D)/.latest.2023.csv $@
hledger import --rules-file rules/opening.rules \
-f $@ $<
make rules to run reports is trivial. I've gone for HTML
reports for the most part, as they're the easiest on the eye. Unfortunately
the most useful report to discuss (at least at the moment) would be a list
of transactions in a given expense category, and the register/aregister
commands did not support HTML as an output format. I submitted my first
HLedger patch to add HTML output support to aregister:
https://github.com/simonmichael/hledger/pull/2000
addressing the virtual posting problem
I wrote in my original hledger blog post that I had to resort to
unbalanced virtual postings in order to record both a liability between
my personal cash and family, as well as categorise the spend. I still
haven't found a nice way around that.
But I suspect having broken out the journal into lots of other journals
paves the way to a better solution to the above.
The form of a solution I am thinking of is: some scheme whereby the two
destination accounts are combined together; perhaps, choose one as a primary
and encode the other information in sub-accounts under that. For example,
repeating the example from my hledger blog post:
2022-01-02 ZTL*RELISH
family:liabilities:creditcard -3.00
family:dues:jon 3.00
(jon:expenses:snacks) 3.00
2022-01-02 ZTL*RELISH
family:liabilities:creditcard -3.00
family:liabilities:jon:snacks
family:liabilities:jon
prefix and combine the transactions with the regular jon:expenses
account heirarchy.
(this is all speculative: I need to actually try this.)
catching errors after an import
When I import the transactions for a given real bank account, I check the
final balance against another source: usually a bank statement, to make
sure they agree. I wasn't using any of the myriad methods to make sure
that this remains true later on, and so there was the risk that I make an
edit to something and accidentally remove a transaction that contributed
to that number, and not notice (until the next import).
The CSV data my bank gives me for accounts (not for credit cards) also includes
a 'resulting balance' field. It was therefore trivial to extend the CSV import
rules to add balance
assertions to
the transactions that are generated. This catches the problem.
There are a couple of warts with balance assertions on every such
transaction: for example, dealing with the duplicate transaction for paying
a credit card: one from the bank statement, one from the credit card.
Removing one of the two is sufficient to correct the account balances but
sometimes they don't agree on the transaction date, or the transactions
within a given day are sorted slightly differently by HLedger than by the
bank. The simple solution is to just manually delete one or two assertions:
there remain plenty more for assurance.
going forward
I've only scratched the surface of the suggestions in Astapov's "full fledged
HLedger" notes. I'm up to step 2 of 14. I'm expecting to return to it once
the changes I've made have bedded in a little bit.
I suppose I could anonymize and share the framework (Makefile etc) that I am
using if anyone was interested. It would take some work, though, so I don't know
when I'd get around to it.
Next.